CS231n 回顾与思考(一)
大三上学期突然入了深度学习的坑,明明还没从机器学习CS229的坑里爬出来就先放一边去了,有空还要去把机器学习的坑填上。当初学的时候忘了做笔记,因为做MIT6.828,结果CS231n有点忘了,现在来补一补笔记。
图像分类
在学习 CS231n 的一开始,先介绍了图像分类的相关知识。首先图像一般是由3个颜色通道构成(红,绿,蓝),所以一张图片一般是个三维数组。图像分类有很多挑战,常见的是图像的拍摄点存在不同,图像的大小,物体的变形,光照影响,和背景颜色类似,同一物体的多种外形等等。所以其中有一种最简单的思路——最近邻分类器。
最近邻分类器
这是一个最基础的分类器。比如,使用 CIFAR-10 这个图像数据集,这个数据集是有 10 种类型的不同图片组成。训练集中每一类都有5000张不同图像,每张图片是32x32的大小。最近邻分类器的简单思路就是判断两张图片的近似程度。这里用到了一个公式 L1 distance:
$$ d_{1} (I_{1}, I_{2})=\sum_{p} \left| I^p_1 - I^p_2 \right| $$
两个图片对于每个像素进行相减取绝对值,然后将这些值求和,得到整个图片的 L1 距离。以下是一个4x4的例子。
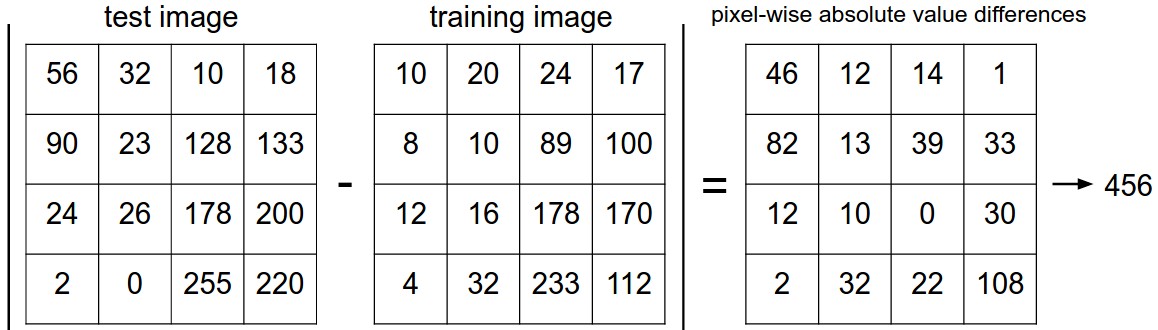
对于要分类的那张未知类的图像,只需要求它与训练集里其他图像的 L1 距离,找到距离最近的图像,就认为未知类的图像是这个距离最近的图像的种类。
对于距离的选择,还有一个公式—— L2 distance:
$$ d_{1} (I_{1}, I_{2})= \sqrt{\sum_{p} \left( I^p_1 - I^p_2 \right)^2} $$
KNN
KNN 思路是找出最相似的 k 个图片的标签,然后取这 k 个中相同标签最多的那个标签。上面的 NN 其实就是 k = 1 的情况。
验证集
对于如何确定超参数,只能通过不停的调试。为了先确定超参数以便预测测试集,可以使用验证集的思路。在训练的时候,不能用测试集来训练模型参数,那样会过拟合。使用验证集的思路是:从训练集中选取一部分当做假的测试集,通过剩余的训练集来训练模型,与假的测试集进行计算准确度,准确度最高的那个超参数可以算是较为合适的超参数。
之后就有一种方法,交叉验证。这是将训练集均分为几份,其中一份为测试集,剩余的作为训练集进行训练,得出准确率。将这些准确率取平均值代表平均准确率。
线性分类器
然而用 NN 来做图片分类还是太麻烦了,所以为了简化计算量,引入了评分函数和损失函数,用来量化图片分类与真实标签的相似程度。
线性分类器就是
$$ f(x_i, W, b) = W x_i + b $$
其中 $ x_i $ 是训练集中的图片,W 是权重, b 是偏移量。对于训练集中的每一张图片,都要它的真实标签 $y_i$。所以就变成需要靠训练集的训练来调出最合适的 W 和 b,使得这个线性分类器 f 能对任意输入的一个图片进行计算操作,得到一个预测的值,预测值与真实值越近越好。
用一张简单的图例就是

对于 W 和 b,有一个小技巧,是将 b 添加到 W 中去,使 W 多一列,这样可以简化运算。
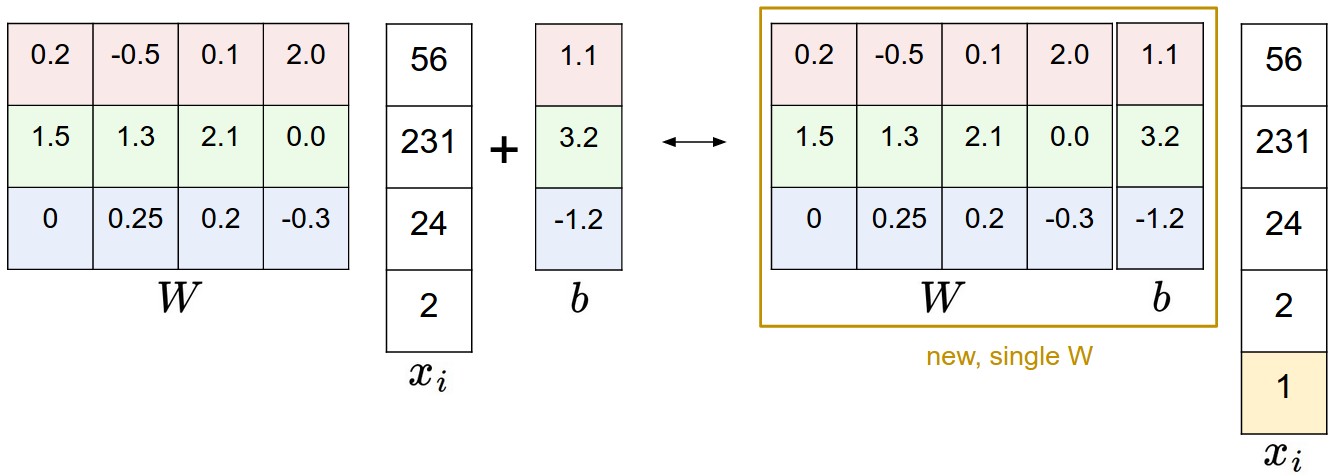
以上内容也不是很难,下面才开始有点难度。
损失函数
上面提到了线性分类器,同样也算是损失函数的计算。只有当 W 和 b 是调好参数的时候,才能作为分类器,不然只能作为得分函数来看。所以 $ f(x_i, W, b) $ 也就是所谓的得分函数。对于得到的得分,需要一个损失函数来量化与正确值之间的差异程度。
多类支持向量机损失
SVM的损失函数是在所有正确分类的得分和不正确分类的得分中确定出一个边界差 $\Delta$。之前提到过,第 $i$ 个数据包含图像 $x_i$ 的像素和代表正确标签的 $y_i$。就数据集 CIFAR-10 而言,类别有10种,所以 $ f(x_i, W, b) $ 计算能得出对于10个类的分别得分,正确的是在类 $i$ ,错误的类标签就是 $j$。那么对于第$j$类的得分就是第$j$个元素:$s_j = f(x_i, W)_j$。根据概念,可以得出 SVM 的损失函数
$$ L_{i} = \sum_{j\neq y_{i}} \max(0, s_{j} - s_{y_{i}} + \Delta) $$
这个函数简而言之就是给定超参数 $\Delta$ 后,所有错误类别的得分减正确类别得分加上 $\Delta$ 之和就是损失值。这里的 $max(0, -)$ 不能遗漏。$max$ 得 0 的意义代表取的超参数 $\Delta$ 是可行的,而不得 0 代表 $\Delta$ 还有点大。
所以使用线性得分函数 $(f(x_i; W) = W x_i)$ 的 SVM 损失函数就是
$$ L_{i}=\sum_{j\neq y_{i}} \max(0, w_{j}^{T} x_{i} - w_{y_{i}}^T x_{i} + \Delta) $$
这里 $w_j$ 是 $W$ 的 第 $j$ 行变形得到的列向量。
所以 SVM 就是为了先计算出合适的 $\Delta$,之后就能用来分类了。下图描述了正确类与错误类之间的差距关系。

正则化
正则化,也就是regularization,是为了避免在训练权重的时候过拟合,这里算是历史原因导致的约定俗成。最常见的是 L2 范式。这是在原本的 Loss 函数后加上正则化惩罚函数,这个惩罚函数是
$$ R(W) = \sum_{k}\sum_{l} W_{k,l}^2 $$
所以完整的 SVM 函数就是
$$ L = \underbrace{ \frac{1}{N} \sum_{i} L_{i} }_\text{data loss} + \underbrace{ \lambda R(W) }_\text{regularization loss} \\ $$
详细点就是
$$ L = \frac{1}{N} \sum_{i} \sum_{j\neq y_{i}} \left[ \max(0, f(x_{i}; W)_{j} - f(x_{i}; W)_{y_{i}} + \Delta) \right] + \lambda \sum_{k}\sum_{l} W_{k,l}^2 $$
这个 $ N $ 就是训练样本的数量。这里也有个超参数 $ \lambda $,当然可以和上面类似,用交叉验证来得到合适的值。