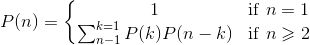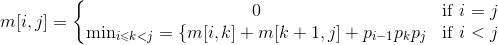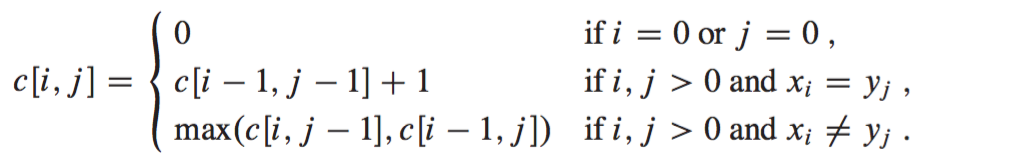import sys defMaxtrixChainOrder(p): n = len(p)-1 m = [[0]*(n) for _ in xrange(n)] s = [[0]*(n) for _ in xrange(n)] for i in xrange(0, n): m[i][i] = 0 for l in xrange(2, n+1): for i in xrange(0, n - l + 1): j = i + l -1 m[i][j] = sys.maxint for k in xrange(i, j): q = m[i][k]+m[k+1][j]+p[i]*p[k+1]*p[j+1] if q < m[i][j]: m[i][j] = q s[i][j] = k return m, s
m, s = MaxtrixChainOrder([30,35,15,5,10,20,25]) print'm:' print'\n'.join(map(str, m)) print's:' print'\n'.join(map(str, s))
print'矩阵链乘法的方案是:',
defPrintOptimalParens(s, i, j): ret = '' if i == j: return'A'+str(j) else: ret += '(' ret += PrintOptimalParens(s, i, s[i][j]) ret += PrintOptimalParens(s, s[i][j]+1, j) ret += ')' return ret
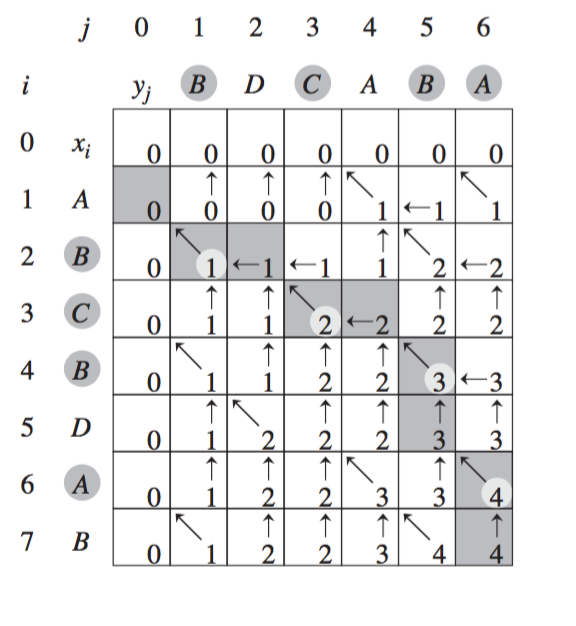
defLCSLength(x, y): m = len(x) n = len(y) b = [[0for _ in xrange(n+1)] for _ in xrange(m+1)] c = [[0for _ in xrange(n+1)] for _ in xrange(m+1)] for i in xrange(1, m+1): for j in xrange(1, n+1): if x[i-1] == y[j-1]: c[i][j] = c[i-1][j-1]+1 b[i][j] = '↖' elif c[i-1][j] >= c[i][j-1]: c[i][j] = c[i-1][j] b[i][j] = '↑' else: c[i][j] = c[i][j-1] b[i][j] = '←' return c, b
defPrintLCS(b, x, i, j): if i == 0or j == 0: return if b[i][j] == '↖': PrintLCS(b, x, i-1, j-1) print x[i-1], elif b[i][j] == '↑': PrintLCS(b, x, i - 1, j) else: PrintLCS(b, x, i, j - 1) x = 'ABCBDAB'.strip() y = 'BDCABA'.strip() c, b = LCSLength(x, y)