几种常见排序算法的学习
排序算法是面试中常被提及的算法种类之一,以下记录了我学排序的一些想法。
插入排序
介绍
插入排序(insertion sort)是最简单的排序算法之一。插入排序由 N - 1 趟(pass)排序组成。对于P = 1 趟到 P = N - 1 趟,插入算法保证从位置 0 到位置 P 上的元素为已排序状态。
1 | void InsertionSort(ElementType A[],int N) |
插入排序的分析
嵌套循环的每一个都花费 N 次迭代,
对所有的P进行求和,得到总数为
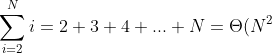)
因此插入排序为。
总结
其实就是从左到右,取每个元素,通过比较让其放在正确的位置。相比同样是的冒泡排序,插入排序减少了交换元素的次数。
希尔排序
介绍
希尔排序(Shellsort),有时也叫缩小增量排序(deminishing increment sort),通过比较相距一定间隔的元素来工作;各趟比较所用的距离随着算法的进行而减小,直到只比较相距相邻元素的最后一趟排序为止。
增量的选择有多种,不同的增量,性能也不同。较为常见的是使用希尔增量。以下是以增量为N / 2的算法。
1 | void ShellSort(ElementType A[], int N) |
###总结
希尔排序的性能取决于增量的选择。希尔排序说白了就是先使相同间隔的元素有序,然后缩写间隔,从而完成整个排序。
堆排序
###介绍
堆排序(heapsort),基于优先队列可以用花费时间的排序的特性。然而实践中它却慢于使用Sedgewick增量序列的希尔排序。
建立堆花费的时间是.
该算法的主要问题在于它使用了一个附加数组。因此,存储需求增加一倍。在每次DeleteMin之后,堆缩小1,将堆中最后一个单元用来存放刚刚删去的元素,即可避免使用第二个数组。
算法分析
堆排序的过程是先建堆,后操作。
建堆
将数组视为一颗完全二叉树,从其最后一个非叶子节点n / 2开始调整。将该节点的儿子节点中,较大的节点与该节点互换。
DeleteMax
将堆中最后一个元素与第一个元素交换,缩减堆的大小并进行下滤,来执行N - 1次DeleteMax操作。
总结
堆排序的总结起来就两步,建堆的部分比较重要,需要慢慢理解才能弄懂。
1 | void PercDown(ElementType A[],int i,int N) |
归并排序
介绍
归并排序以最坏情形运行时间运行,而使用的比较次数几乎是最优的。它的基本操作是合并两个已排好序的表。基本的合并算法是取两个输入数组A和B,一个输出数组C,以及三个计数器Aptr,Bptr,Cptr,它们初始置于对应数组的开始端。A[Aptr]和B[Bptr]中的较小者被拷贝到C中的下一个位置,相关的计数器向前推进一步。当两个输入表有一个用完的时候,则将另一个表中的剩余部分拷贝到C中。
合并两个已排序的表的时间显然是线性的,因为最多进行了N-1次比较,其中N是元素的总数。
该算法是递归地将前半部分数据和后半部分数据鸽子归并排序,得到排序后的两个部分数据,然后使用上面描述的合并算法再将这两部分合并到一起。这是经典的分治(divide-and-conquer)策略,它将问题分成一些小的问题然后递归求解,而治的阶段则将分的阶段解得的各个答案修补到一起。
1 | void MSort(ElementType A[],ElementType TmpArray[],int Left,int Right) |
Merge函数的精妙在于任何时刻只用一个临时数组活动,而且使用该临时数组的任意部分。
算法分析
1 | // Lpos = start of left halt,Rpos = start of right half |
总结
虽然归并排序的运行时间是,但它很难用于主存排序,主要问题在于合并两个排序的表需要线性附加内存,在整个算法中还要花费将数据拷贝到临时数组再拷贝回来这样一些附加的工作,其结果严重放慢了排序的速度。这种拷贝可以通过在递归交替层次时审慎地转换A和TmpArray的角色得到避免。
快速排序
介绍
快速排序(quicksort)是实践中最快的已知排序算法,它的平均运行时间是。快速排序也是一种分治的递归算法。讲数组S排序的基本算法由下列简单的四步组成:
- 1: 如果S中元素个数是0或1,则返回。
- 2: 取S中任一元素v,称之为
枢纽元(pivot)。 - 3: 将S - {v}(S中其余元素)分成两个不相交的集合:
)和
。
- 4: 返回{quicksort(
))后,继随v,继而quicksort(
))}。
算法分析
选取枢纽元
枢纽元的选取对算法性能的影响很大,一种错误的方法是选择第一个元素用作枢纽元,另一种想法是选取前两个互异的关键字中较大者作为枢纽元。一种安全的做法是随机选取枢纽元,然而随机数的生成一般是昂贵的,根本减少不了算法其余部分的平均运行时间。比较常用的是三数中值分割法(Median-of-Three Partitioning)。枢纽元的最好的选择是数组的中值。然而这很难算出。一般的做法是使用左端、右端和中心位置的三个元素的中值作为枢纽元。
小数组
对于很小的数组(N<=20),快速排序不如插入排序好。通常的解决方法是对于小的数组不递归的使用快速排序,而代之以诸如插入排序这样的对小数组有效的排序算法。一种好的截止范围(cutoff range)是N=10。
算法核心
快速排序真正的核心包括分割和递归调用。选取枢纽元最容易的方法是对A[Left]、A[Right]、A[Center]适当地排序。将三元素中的最小者放在A[Left],这正是分割阶段应该将它放到的位置。三元素中的最大者被分在A[Right],因为它大于枢纽元。因此,我们可以把枢纽元放到A[Right-1]并在分割阶段将i和j初始化到Left+1和Right-2。
1 | ElementType Median3(ElementType A[], int Left, int Right) |
for循环里的两个while循环,实现了从左到右和从右到左寻找第一个不满足条件的元素进行交换。
总结
在理解堆排序和归并排序后,快速排序的理解就容易对了。和归并排序一样,难点都在于递归的调用。快速排序的细节也需要注意,稍微一个改变都有可能使该算法不能正确运行。
(To be continued)