MIT 6.824 Lab1 MapReduce
MIT yyds,真的爱了爱了
MIT 6.824真的是我拖了很久都一直想做的Project,以前本科的时候做完CSAPP以后,就挖坑做MIT 6.828,另一个目标就是做6.824。当时奈何Go并没怎么学,所以一直拖着连Lab1都没有认真做完。终于弄完毕业论文,找完工作以后这段摸鱼时光,想起年少的理想还没实现,于是赶紧打论文,看lecture,参考了一堆资料,开始写Project。
准备
首先是阅读论文,2020版的作业相比以前,需要自己实现RPC部分,因此相对于以前只需要实现MapF和ReduceF,首先需要设计好RPC交互。
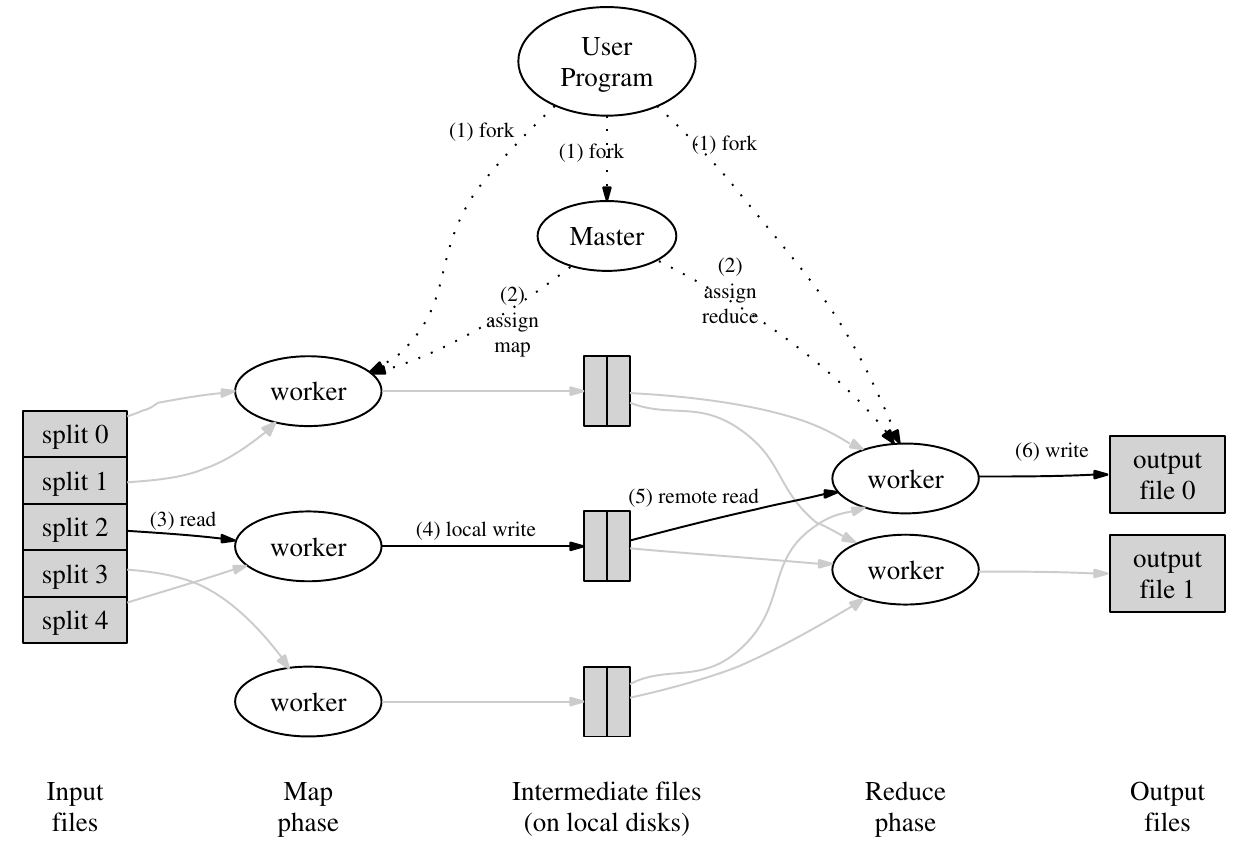
RPC主要是Master和Worker之间的通信,Master负责调度任务,Worker的注册以及将任务给Worker进行运行。Worker首先上线以后会去Master注册,获取workID,之后不断的获取任务,执行任务,反馈任务执行信息。如果Worker执行某个Task失败,会通知给Master,让其找其他可以运行的Worker重新执行该Task。
Worker
在复盘Lab 1时,感觉先写Worker会比较好理解,Master负责调度以及使用Worker来进行工作。Worker的几个工作相对好理解。对于MapReduce来说,Worker是不需要考虑map函数和reduce函数具体细节,更多是关注如何将map的结果写到本地磁盘,以及reduce函数如何读取数据进行合并输出结果。
注册
当worker上线后,第一步是发消息给Master进行注册自己的信息。
//
// main/mrworker.go calls this function.
//
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
w := worker{}
w.mapf = mapf
w.reducef = reducef
// uncomment to send the Example RPC to the master.
//CallExample()
w.register()
w.run()
}
刚才说了,Master负责全部资源的调度和任务分配,因此Worker去注册自己的身份,主要是为了获得自己的workerID,这样后续的相应操作Master都可以知道是哪个Worker进行的请求。
func (w *worker) register() {
args := &RegArgs{}
reply := &RegReply{}
if ok := call("Master.RegWorker", &args, &reply); !ok{
log.Fatal("Register worker fail.")
}
w.id = reply.WorkerId
display(fmt.Sprintf("worker %+v register\n", w.id))
}
请求任务
Worker向Master请求,获取当前需要执行的任务信息。
func (w *worker) reqTask() Task {
args := TaskArgs{}
args.WorkerId = w.id
reply := ReqTaskReply{}
if ok := call("Master.ReqTask", &args, &reply); !ok {
log.Fatal("request for task fail...")
}
return *reply.Task
}
运行阶段
Worker在运行的阶段,实际上是一直轮询,从Master获取需要执行的任务,直到所有任务都结束。
func (w *worker) run() {
for {
t := w.reqTask()
if !t.Alive {
display(fmt.Sprintf("worker get task not alive, worker %d exit..\n", w.id))
return
}
w.doTask(t)
}
}
执行任务
之前的图中可以看到,Worker实际上也是有两个阶段的,一个是Map阶段,一个是Reduce阶段。每个任务不同阶段,因此在执行的时候,要根据任务的阶段执行不同的操作。
Map任务与Reduce任务
Map阶段使用mapf对内容构建出键值对,将所有的kvs通过hash放到中间文件中。按照Task的任务量(lab里也就是文件数量)和Reduce块数构建成中间文件矩阵。
Reduce阶段分为两部分,首先是读取文件,将本地的中间文件读取出来,之后进行reduce操作,其结果最后会写到本地的分块文件中。
Master
Master的职责就比较多,自顶向下来看,MakeMaster 是Master的入口,这里包含初始化Master节点,初始化Map任务相关状态然后启动Master的服务。
对于刚开始的任务,是处于Map阶段,从任务状态里将所有的Task添加到Task队列中,方便Worker获取Task进行执行。在运行阶段,通过计算任务执行之间来进行超时控制,当超过一段时间并没完成后,会将该任务重新塞回任务队列。通过不断的循环,当所有任务的Map阶段都完成好后,转为Reduce阶段。
// schedule task
func (m *Master) schedule() {
//fmt.Println("Processing ...")
// check all task status
flag := true
m.mu.Lock()
defer m.mu.Unlock()
if m.done {
return
}
for id, taskStat := range m.taskStats {
//fmt.Printf("Task %d : %v", id, taskStat.Status)
switch taskStat.Status {
case TaskStatusReady:
flag = false
m.addTask(id)
case TaskStatusQueue:
flag = false
case TaskStatusRunning:
flag = false
m.checkBreak(id)
case TaskStatusFinished:
// 只有全部任务都是完成,才不会对flag变量进行修改,
// 进入reduce环节
case TaskStatusErr:
flag = false
m.addTask(id)
default:
panic("Tasks status schedule error...")
}
}
if flag {
if m.taskPhase == MapPhase {
m.initReduceTasks()
} else {
m.done = true
}
}
}
当Worker向Master请求任务后,从任务队列中获取一个Task,然后将该Task的相关信息传给Worker,并且在Master处注册该任务,也就是修改维护的任务状态信息。Worker在执行的过程中,也会不断反馈任务相关执行状态。
Ref
MapReduce: Simplified Data Processing on Large Clusters
MIT 6.824 Lab1 MapReduce 2020 攻略
6.824 Spring 2020 – Lab 1: MapReduce